Written by
Nickolay Shmyrev
on
Multistream TDNN and new Vosk model
What I really like in speech recognition and what keeps me excited about
it is an active on-going development of speech recognition technology
which boosts both speech recognition results and, more importantly,
understanding of speech recognition theory. It is never boring.
Last year advancement beside new big datasbases are exciting model
architectures. One is Conformer architecture in end-to-end recognizers,
another is multistream TDNN for Kaldi.
The multistream multi-resolution TDNN is introduced in the paper:
Multistream CNN for Robust Acoustic Modeling by Kyu J. Han, Jing Pan, Venkata Krishna, Naveen Tadala, Tao Ma (ASAPP) and Dan Povey (Xiaomi)
The architecture looks like this:
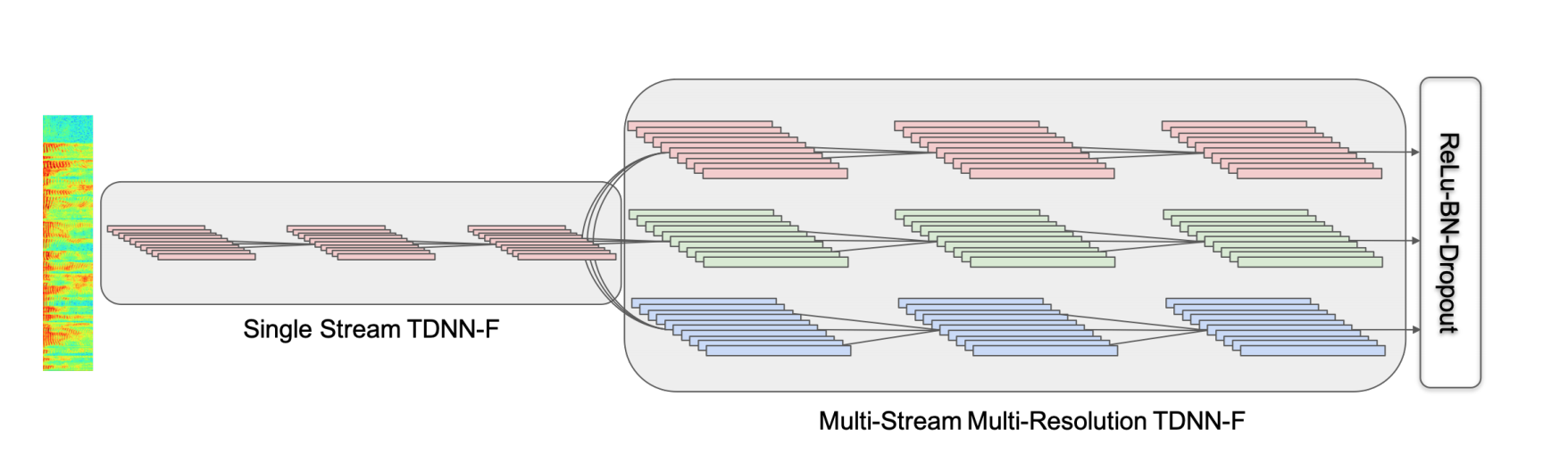
Recipe is here:
https://github.com/asappresearch/multistream-cnn
The main idea is that we combine multi-resolution streams which work on
step 3, step 6, step 9 and step 12 in the network thus we better handle
multi-scale speech sounds. Slow changing sounds go through path with step
12, faster with path with step 3. The idea is amazing and once again
shows the importance of the context. Accuracy and speed results
demostrate the avantage of the approach.
We spent some time training multistream models and can give some notes on
the paper and approach:
-
Authors give a bit confusing name Multistream-CNN to the architecture
which causes issues with understanding. Actually, they describe two
architectures - pure multistream TDNN-F (just TDNN-F with multistream
branches) and 2D-CNN-TDNN-F (multistream TDNN-F with 2D-CNN frontend) which
they use for Librispeech only, not for comparision with the baseline in production. One
can think they use 2D-CNN-TDNN-F everywhere since it is the one which is pushed to recipe above
but it is not the case.
-
Multistream 2D-CNN-TDNN-F is crazy slow both for training and decoding,
not practical at all. I believe authors just used it for Librispeech to
get 1.7% WER cited everywhere. I believe for practical applications
authors used just multistream TDNN-F which is not present in recipes but
which can be compared with simple TDNN-F model and gets the improvements
described in the paper. On the image above they do not have CNN layers
for example.
-
It is not clearly documented but such a complex architecture requires longer training
and smaller learning rate. If before it was ok to train 2k hours for 2 epoch with Kaldi, now
you need 6 epoch to get best results and smaller learning rate. And this is critical to
get a great accuracy. We spent quite some time training different variants until we got
reasonable accuracy improvement.
-
New CNN recipes in Kaldi use specaugment/batchnorm and do not use
dropout. Dropout topic is really interesting since dropout is a powerful
regularization method. On the same time it is believed to be harmful
[1],[2]
for CNN, so it is natural Kaldi has specaugment/batchnorm for CNN-TDNN.
However, for TDNN without CNN I believe that dropout is more useful than
specaugment and earlier Kaldi experiments confirmed that. Conformers
training also use dropout together with specaugment. So while it requires
more experiments, I belive we need to keep dropout in the recipes.
-
Dropout in kaldi has schedule, it is active in the middle of training
and disabled till the end. Specaugment works all the time. It would be
nice to have schedule for specaugment too.
-
While 2D-CNNs are slow it is certainly interesting and promising to replace them with
TDS
convolutions
which are going to be much faster. TDS convolutions are used in many
modern architectures like conformer for example. Unfortunately that will
require more coding in Kaldi. Or, we need to move to Python for acoustic
models eventually.
-
Multistream accuracy is defined by much wider context the network uses.
Instead of context of 50 before it is now 150 frames on the left and 150
frames on the right. Such a long context is exciting but it introduces
significant latency in recognizer. You have to wait almost 2 seconds to
get result. A version with only left context needs testing since it is
expected to have different accuracy point too.
-
We can’t confirm 6-9-12 as in the paper works best. For us, 3-6-9
sounds more reasonable.
So the paper idea and overall thing is very exciting and promising, but
some important things are not yet clear and model requires more code,
training and experiments.
We have a trained a nice US English model already which we can use for
testing. It is significantly better than the models we have before
(Daanzu) but it is not yet finished. Requires more experements and more
data in the training and more time. We need to add telephony data to the
training as well as many other datasets now available.
The model is not as accurate like Nemo Conformer yet but it is pretty
practical and also it can work much better with custom LMs for custom
domains where Conformers are not that shiny.
The model is available here:
http://alphacephei.com/vosk/models/vosk-model-en-us-0.20.zip
Here are the accuracy results which the model:
| Dataset |
Vosk Aspire |
Vosk Daanzu |
Vosk 0.20 |
Nvidia Conformer-CTC |
| Librispeech test-clean |
11.72 |
7.08 |
6.27 |
2.26 |
| Tedlium test |
11.23 |
8.25 |
6.93 |
4.89 |
| Podcasts |
19.85 |
21.21 |
18.53 |
13.79 |
| Callcenter 1 |
53.98 |
52.97 |
46.48 |
32.57 |
| Callcenter 2 |
33.82 |
43.02 |
41.00 |
27.82 |