Written by
Nickolay Shmyrev
on
Brain, Time, CTC blank states and streaming
It is interesting that the longer we study the reality the more unusual it appears to us. For example, if we think about
brain, there are two important ideas we can infer from our current understanding of brain mechanics:
- Brain actions are triggered by very short events - spikes
- Brain is a highly parallel system
These two propositions have important consequences in design of the speech systems. For example, if we consider
individual sounds we produce, most likely they are generated with some spikes inside the brain which means there
are moments we have a real spike in electrical activity. And if we model them in software we should have those spikes too.
This moment is actually already worked out in speech recognition. We moved from 9-state HMMs for TIDIGTS to 3-state HMMs for GMM-HMM systems
to CTC architecture which exactly follows the function of the brain - there is quiet blank state and a spike state corresponding to sound. This architecture is efficient both in terms of memory and speed. There are
disadvantages too, CTC might loose the best path while jumping in the blank state thus it can skip words in noisy inputs. But in general I find
the idea has not just exerimental grounds but also theoretical grounds.
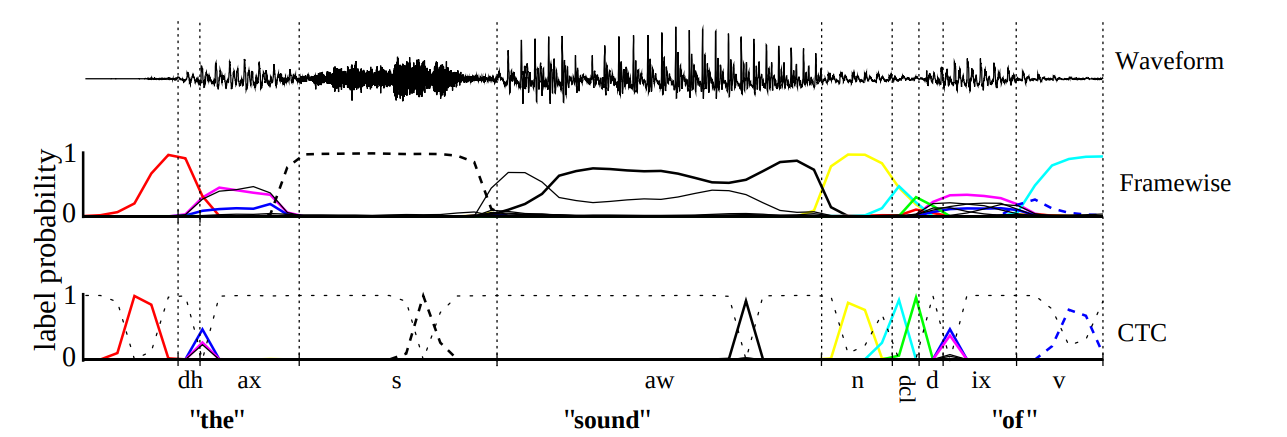
These theoretical grounds are not frequently mentioned in the publications and lectures that explain CTC. While reading CTC papers
before I never associated the word “spike” with the actual brain spike. For example, if you read the original CTC paper you might have impression
that this architecture is just a good guess by the authors.
It seems to be we well worked out in speech recognition, but similar design decision are made in other areas. For example, there is blank state in Glow-TTS text encoder achitecture which is also used in VITS1 and then dropped in VITS2 without much explanation. People wonder what is
that and why is it required, for example this issue. Author even claim there is no theoretical basis. For my opinion given the blank
architecture is justified, the decision to drop in in VITS2 seems to be wrong. Our experiments training VITS models with blank state and without it confirm that as well.
Another area is still speech recognition but more high-level spikes. Modern LMs popularized tags for languages, special events, etc. Like translation or language tag in Whisper. They work efficiently
compared to encoding language as an additional dimension. But we rarely think of them as actual brains spikes.
Ancient Greeks knew three types of time: Chronos as a continuous linear time, Cyclos as a repeating sequence of events, Kairos as a unique moment.
Since Newton everything got reduced to just a linear time, but in the middle of the 20th century other concepts got back. Quantum mechanics did a big shift but also invention of computers. Here one can cite a fundamental works of Leslie Lamport on logical time, for example
Time, Clocks and the Ordering of Events in a Distributed System
If we think about second point about parallel processing in the brain, we can actually infer that time in the brain is really non-linear. It is
more Cyclos than Chronos. And if we apply philosophy to speech recognition, we need to review the approach to continouos streaming
decoding. I’ve been a long proponent of the fast streaming decoding with low latency response but given the proposition I now think it is not really the way human brain works. Instead, we process incoming data in parallel, meaning we do not have to always generate the response with
very small latency. We have a certain landmarks in time (think of spikes) where we update our brain state using parallel processing.
Recently there is a lot of efforts to reduce ASR latency but they kind of fail. Streaming error rates are way higher than non-streaming ones.
People have to apply two-pass processing, think of U2 architecture. Some teams, for example Whisper and Silero teams got the right idea that continuous low latency is not
really needed. Instead we can process audio with non-streaming architecture at certain points in time and get a response faster and, more importantly, that response will be more accurate. But we need a
trigger. As a first approximation, a good VAD could serve as a trigger. In a longer term, we can build a trigger network that will start parallel
processing at the moments of low entropy or other important moments but not too frequently.
So instead of experimenting with architectures we can really deduce the optimal one from the understanding of brain mechanics, it allows
use to justify the decisions made and move into the right direction. Of course, a lot of research here, but not well understood by speech
engineers. For example
Enhancement of speech-in-noise comprehension through vibrotactile stimulation at the syllabic rate
Related paper:
Spiking Music: Audio Compression with Event Based Auto-encoders