Written by
Nickolay Shmyrev
on
Why discrete units
Discrete units made a splash since Hubert probably (2021, four years
already), then with Tortoise TTS and successors. Before that there were
many attempts too, like the very old system by our respected colleagues
Jan Cernocky, Genevieve Baudoin, Gerard Chollet
The use of ALISP for automatic acoustic-phonetic transcription 1998.
Originally I was sceptical about discrete units for speech. As usual it
is hard for me to understand things quickly. It seemed for me that speech
is really continuous as the generation part is clearly mechanical.
However, these days I see more and more arguments for discrete units. You
say haha, it has been a few years already, I’d reply - only now we have
enough evidence.
Even now, the theory behind discrete units is somewhat lacking. There is a
definite understanding why they are required but it is certainly not
expressed well or widely accepted. Let’s take a recent work on replacing
discrete units with continouous representation:
Continuous Autoregressive Models with Noise Augmentation Avoid Error Accumulation
https://arxiv.org/abs/2411.18447
It says “This discretization allows models to operate within a discrete
probability space, enabling the use of the crossentropy loss, in analogy
to their application in language models. However, quantization methods
typically require additional losses (e.g., commitment and codebook
losses) during VAE training and may introduce a hyperparameter overhead.
Secondly, continuous embeddings can encode information more efficiently
than discrete tokens…”
While the first sentence is the core advantage of discrete units the second
sentence is not aligning with the theory. The point is that many
distributions we try to model are significantly non-gaussian. We will
cover that later in detail but that’s the fact. And when we try to model
non-gaussian distributions with gaussian models and L2 loss we fail
totally. And flow/flow matching/diffusion models don’t help here since
they still keep that gaussian nature even if they try to approximate the
target distribution. This is exactly the reason we need discrete
approximation and crossentropy loss.
Given that it is strange that the paper above tries to fight error
accumulation but never mentions which distributions it tries to model.
And only provides experimental evidence of the advantages.
Hung-yi Lee talk
This whole idea actually was very nicely introduced to me in a talk by
Professor Hung-yi Lee at Interspeech 2024, see here
https://x.com/HungyiLee2/status/1830698181757411769
Here is the image from the slides:
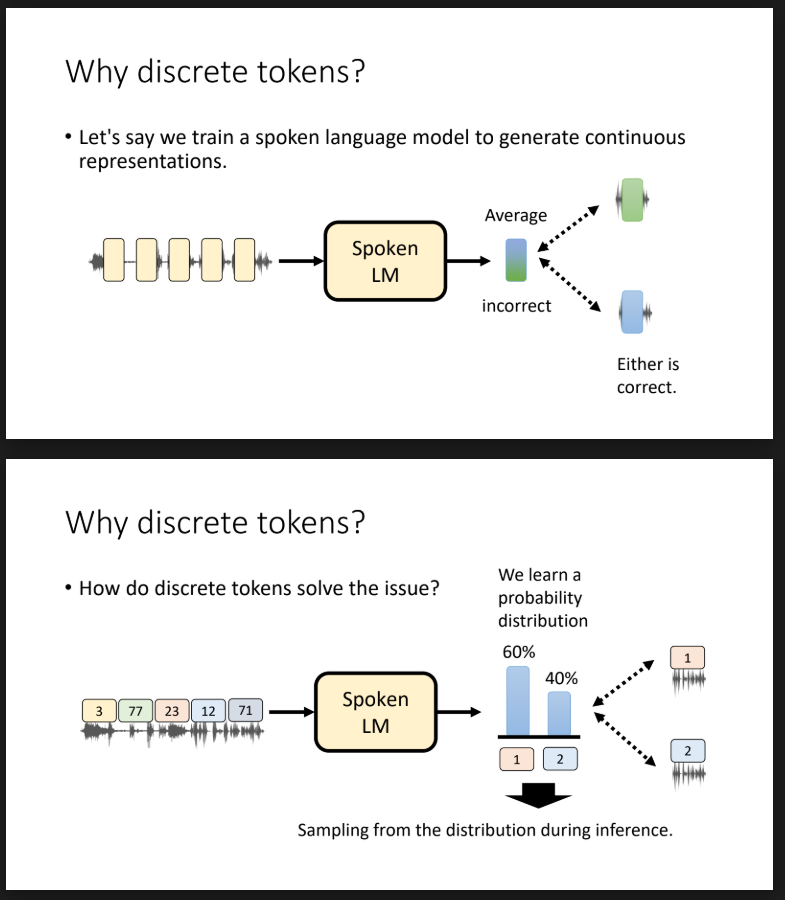
This is probably very obvious thing but I haven’t seen the paper that
uses or mentions this consistently.
Discrete units for duration
Why did this idea come to my mind again? Because we worked a bit more on VITS durations. Here
is the histogram of overall durations values and their VITS prediction.
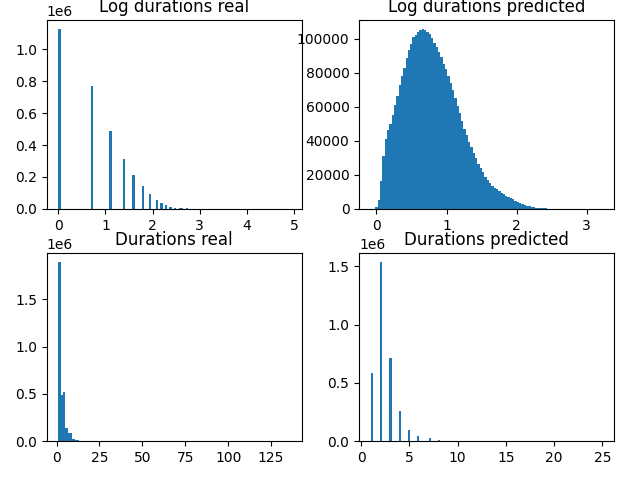
As you see, durations are clearly non-gaussians and simple convnet has trouble to model
them. Not surprisingly, flow model and flow matching model have trouble too!
The solution is simple, let’s consider duration as discrete units and use
cross-entropy loss. Where did we see it already? In
StyleTTS2
I must admit again, StyleTTS2 is very advanced and well-thought
architecture and while it might not be obvious from the start, it
definitely needs attention. Many things like advanced discriminators, ASR
alignment, durations raise again and again in my studies.
StyleTTS2 never calls duration discrete yet, but the idea is the same.
I’d predict the next generation duration model will be all discrete.
This idea is used not just in StyleTTS. For example in the latest paper
Total-Duration-Aware Duration Modeling for Text-to-Speech Systems
we also see Microsoft researchers consider discrete units and prove their advantage.
On top of that, our experiments with StyleTTS2 duration in Matcha TTS show very good
results.
Unit selection vs generative models
That non-gaussian nature of things reminded me of the old story where
everyone was discussing unit selection TTS vs HMM TTS. The first was more
natural-sounding but less flexible, the second never sounded well but was
really versatile.
Since we model something non-gaussian, unit selection and patch mixing
can provide really good results. So welcome back to the unit selection world.
Papers like this appear quite often. One example is
KNN-VC. And DiT/MaskGIT is exactly
the thing here. They are on the rise, and it is nice to have a theory
that confirms they are really reasonable.
Why brain signals are discrete
Clearly some distributions are more gaussian, some less. We need to
understand nature before we select the method. But the question
raises why many of our distributions are discrete.
In my opinion there is a simple answer here - the mechanics of the brain.
Since neurons have pretty fixed states it is natural to think they are
discrete. Somewhere I hear 4-bit estimation from neuroscientists (probably
4-bit LLMs also make most sense). So no wonder that our speech has a
discrete nature as well. Something to remember about.