Written by
Nickolay Shmyrev
on
Experiments with solvers and decoding-time guidance in flow matching
Some features are somewhat small and require few lines of code, not
really worth a conference paper or a poster. Still, they are somewhat
widespread. A blog post about them feels just right.
In P-Flow paper P-Flow: A Fast and Data-Efficient Zero-Shot TTS through
Speech Prompting there is a
big section on guided sampling. Authors claim that pronunciation clarity
can be further enhanced by applying techniques from a classifier-free
guidance method.
The code implementation is really simple, you just run estimator on mean and change the gradient:
https://github.com/p0p4k/pflowtts_pytorch/blob/master/pflow/models/components/flow_matching.py#L168
Here are our experiments with guided sampling and different solvers.
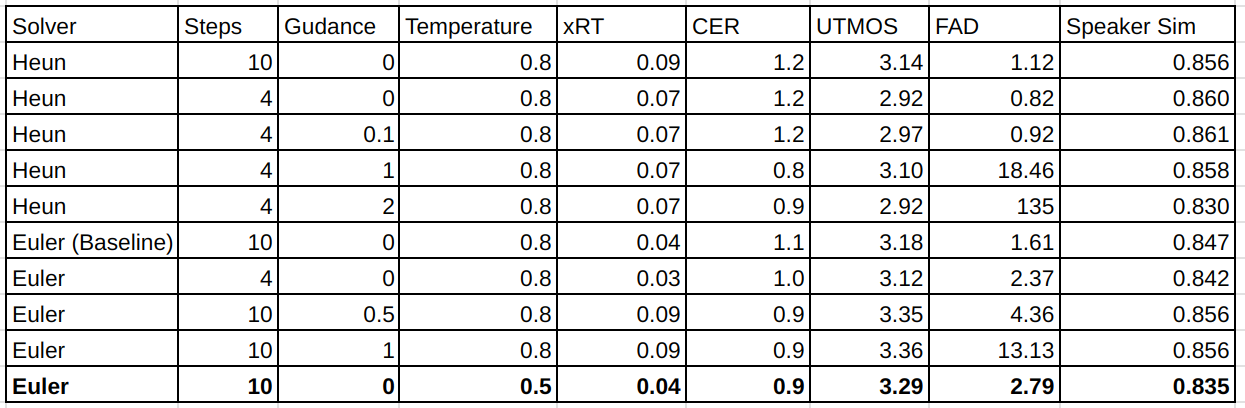
As you see, as any regularization method it helps to reduce artifacts and
improve clarity (see that CER is reduced). It also significantly reduces
expressiveness (see that FAD significantly increased). However, one can
see that simply reducing temperature has similar effect. The question
then is why do we spend compute time on guided sampling. I’ve seen that
many times that researchers propose some different regularization method
but never consider alternatives.
As for solvers, I don’t see any effect from 2-nd order Heun solver. Maybe
diffusion has to be fixed first (replaced with DiT).
Between, default VITS temperature of 0.8 is pretty high and often leads
to artifacts, I’ve heard many times in discussion that production guys
use lower values up to 0.2-0.3. Voice is not that expressive, but
artifacts are significantly reduced.
Between, Matcha/VITS also have problems with modeling speakers. Next post about it.
Update 03.2025
Btw, the original paper
Classifier-Free Diffusion Guidance
claims that low temperature mode results in bad samples and CFG works
better. That’s for pictures. Not sure if the same applies for TTS. But we
ended with CFG at the end too. With weight like 1.0 the quality of the
results significantly improves and the FAD doesn’t degrade much.
Also, from the paper it is clear that CFG must be applied to both
training and inference, not just inference. NVIDIA paper is wrong here.